
MLsys Note (2) - Flash Attention algo & code walk through

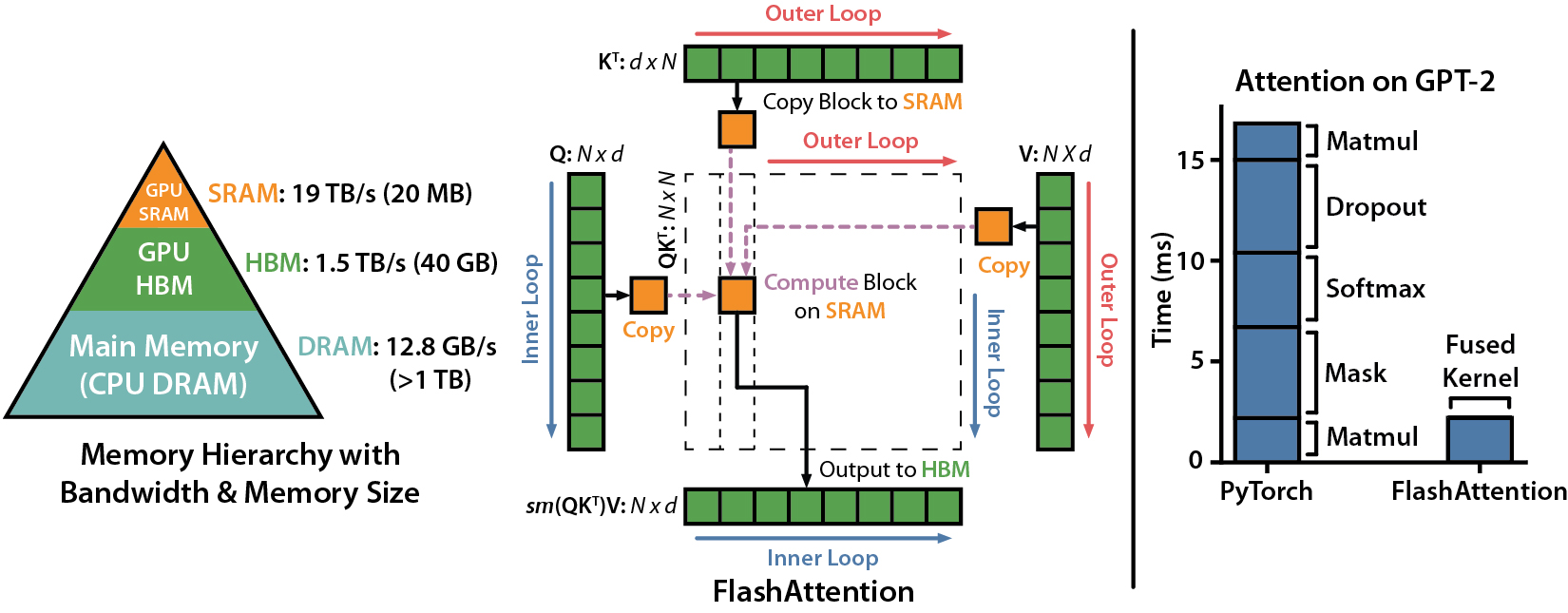
Flash Attention
相關背景應該不用多做介紹,一言以蔽之:
- FA利用online softmax技巧壓縮softmax時帶來的顯存壓力
- 系統上做資料搬運上的kernel優化(kernel fusion),達到高效的inference速度以及少量的顯存用量。
先看算法,再看系統
Flash Attention in Math ref
Naive Attention:
Softmax:
naive softmax不是associative的(summation),也就是說在cuda kernel的實作上,沒辦法被tile優化。
Online Softmax
Safe softmax: 避免exponential function造成過大的值,softmax有個很好的性質 ->
where , 保證
使得fp16在數值計算上更加準確。
有了這個性質,我們可以整理出一個3-pass的算法,讓我們不需要一次load n個component到SRAM裡,而是iterative:
- 先計算 for in
- for in
- for in
雖然成功節省顯存,我們卻需要iterate N sequence三次,這樣在系統上是I/O inefficient的,如果把前兩個operation fuse在一起,可以減少data搬運次數,但我們發現第二個計算是depends on ,不能把他fuse在同一個loop裡,於是就有了online softmax,的遞迴性質:
2-pass算法:
- , for in
- for in
有沒有辦法更近一步變成1-pass?答案是不行,在數學裡的話。
但是我們要計算的是self-attention,我們不只要求出attention score,還需要乘,如果把考慮進來呢?
為了計算出,能不能套用之前的遞迴技巧呢?
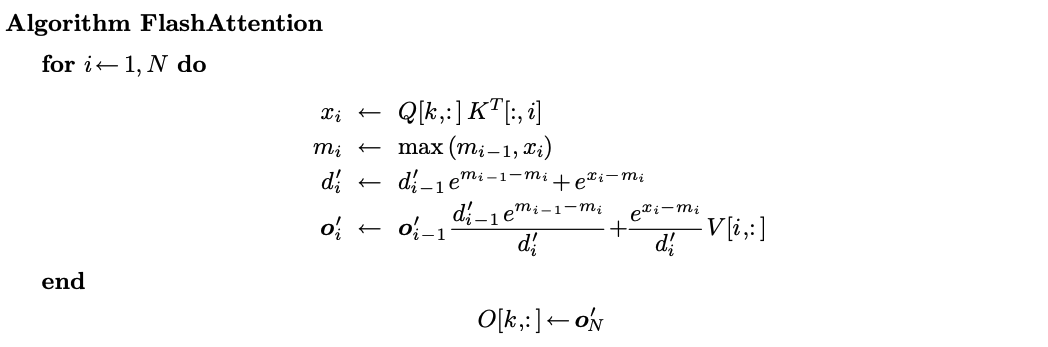
這就是flash attention數學算法,接下來再運用tiling優化kernel就是完整的flash attention了。
Implementation walk thorugh
tiling: 在計算大矩陣時,分成小塊放入block,讓同一塊資料被重複使用,以減少資料搬運的時間。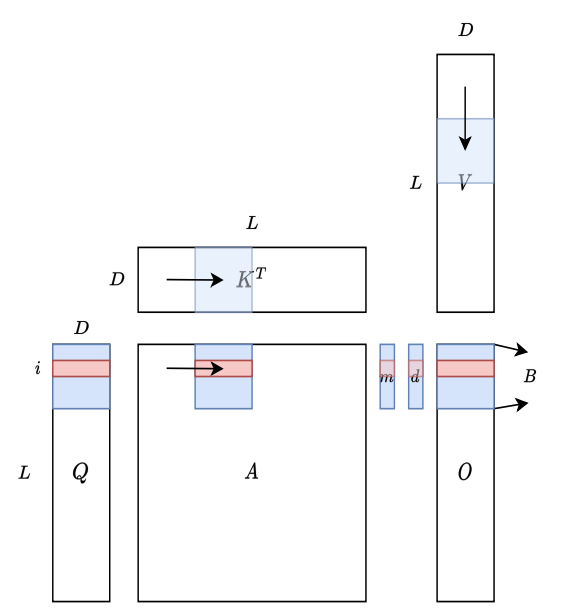
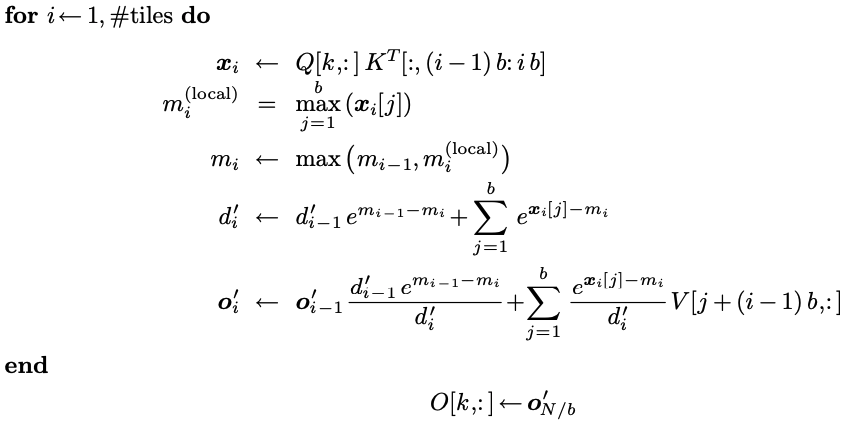
用CUDA進行實現:(解釋概念不保證完全正確)
1 | |
Comments